
En esta página
Seguramente has oído hablar anteriormente del Web Scraping, sobre todo si trabajas con análisis de datos, pero no sabes qué es o como se realiza. En esta guía te explicamos todo lo que necesitas saber sobre técnicas de Scraping en la Web y cómo puedes empezar a ello hoy mismo sin conocimientos de programación.
¿Qué es el Scraping?
Con Web Scraping nos referimos a las técnicas de extracción, clasificación y almacenamiento de datos que se encuentran en una página web o app. Por ejemplo, extraer precios de una tienda online de la competencia y así poder hacer nuestros estudios de mercado se haría con Scraping de datos.
Los datos que proporcionan las webs son públicos y cuentan con un determinado valor, por ello resulta muy interesante tenerlos clasificados y almacenados para múltiples usos.
Sin embargo, las webs no nos proporcionan los datos en el formato que queremos: cuando realizamos una petición a la página web nos devuelve un HTML, un CSS y un Javascript que mostrarán la información al usuario en su navegador web con diferentes estructuras y estilos. No nos lo devuelve en un formato de datos estructurado como podría ser JSON.
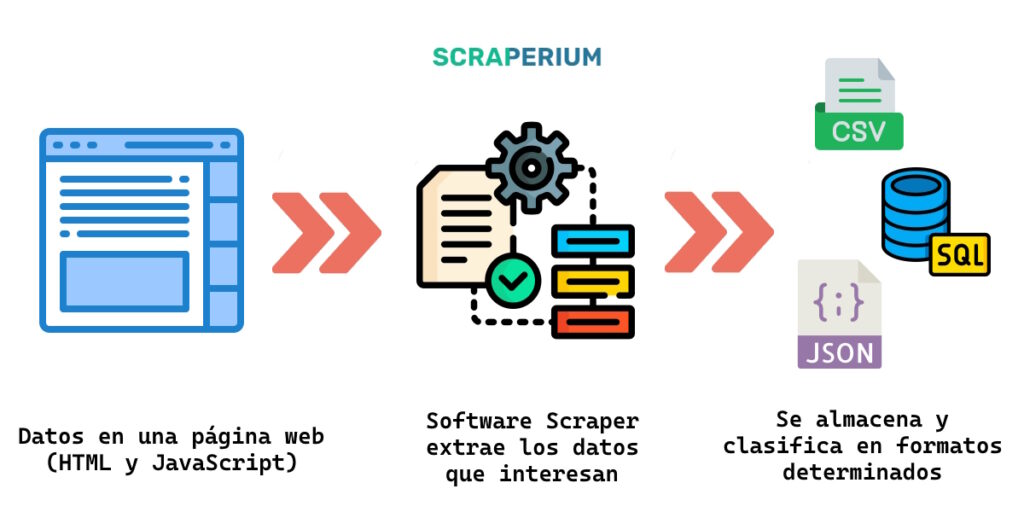
Por ello, pasar datos de una web a Excel por ejemplo no resulta tan sencillo. Además, muchas webs implementan técnicas anti-robots para prevenir la extracción de datos. Recordemos que los datos son valiosos, así que aunque se muestren para el usuario final, no interesa que se tenga directamente en una base de datos por la competencia o terceros.
Formas de realizar Web Scraping
Para extraer y clasificar datos podemos hacerlo de distintas maneras:
- Scraping manual: se trata de acceder a las webs y extraer los datos manualmente a otro formato (hacer copia y pega). Es una tarea larga y repetitiva ya que tendremos que acceder uno por uno a todas las páginas concretas dentro de la web. Sin embargo, a modo de verle una ventaja, los detectores anti-bots que puedan estar presentes en la web no te detectarán como un robot ya que se tiene un comportamiento humano.
- Scraping semi-automático: con la ayuda de extensiones del Google Chrome o Firefox podemos extraer datos de la página que estamos visualizando y guardarlos en el formato que queramos. Con esta opción tendremos el mismo problema de realizar una tarea repetitiva de forma manual. Nos ahorrará tiempo pero para grandes cantidades de datos resulta igualmente tedioso. Si te interesa puedes revisar algunas extensiones para Chrome que te ayudarán con esta tarea.
- Scraping automático: realizado con programas o extensiones robot, trabajan con un navegador concreto sin que el usuario tenga que hacer nada aparte de indicar de dónde y cómo extraer los datos. Podemos programarlo nosotros mismos mediante lenguajes como Python o Java y librerías como Selenium o Puppeteer, o contratar un servicio de scraping profesional.
Scraping automatizado mediante robots scrapers
Realizar scraping manual o semi-automático no resulta útil cuando tenemos una gran cantidad de datos para extraer. Para realizar Web Scraping de manera automatizada, contamos con la ayuda de softwares especializados en extracción de datos llamados scrapers.
Los scrapers o raspadores de datos son programas informáticos encargados de extraer, clasificar y almacenar datos procedentes de páginas webs o apps automáticamente. En general los scrapers realizan los siguientes pasos:
- Visitan la página web en cuestión o llaman a la API correspondiente.
- Esperan a que cargue la página o que la API devuelva la respuesta correspondiente.
- Procesan y extraen los datos según la disposición de la web (mediante selección de los elementos del DOM) o según el formato que obtenga de la web (por ejemplo JSON).
- Almacenan la información en un formato de salida. Los más populares son CSV, JSON, XML, SQL (base de datos) o mediante una API.
El usuario que desee scrapear determinadas webs deberá configurar el robot para que visite y extraiga los datos que considere útiles. Evidentemente los datos irrelevantes se descartan.
Además, tendrá que manejar la paginación de los datos ya que es habitual que no se incluyan todos los datos en una sola petición. Suele aparecer como página 1, 2, 3, etc según los resultados disponibles o directamente un scroll infinito en el que el usuario va deslizando la página hacia abajo y se cargan los resultados de manera asíncrona.

¿Para qué sirve hacer Web Scraping?
La extracción de datos de una web puede servir para muchas tareas. Algunas de ellas son:
Sectores donde resulta útil hacer scraping
- Análisis de la competencia: extraer y analizar los datos de las webs de la competencia para saber qué funciona y qué no. Por ejemplo, extraer los precios de la competencia y actuar en consecuencia, o ver qué productos tienen más popularidad en la web de tus competidores.
- Fuente de datos para estadísticas: con una gran cantidad de datos se pueden hacer estadísticas sobre un nicho de mercado concreto, una zona, un producto o servicio concreto, etc. Por ejemplo, conocer el precio medio del metro cuadrado en una zona concreta. Aplicando técnicas estadísticas se pueden hallar multitud de datos de interés.
- Conocer las tendencias: se realiza seguimiento de una determinada web y se construye una base de datos actualizada con cierta frecuencia. De esta manera podemos tener un histórico con las variaciones en los precios, novedades y productos que dejan de venderse.
Resulta muy interesante recolectar estos datos en diversos sectores profesionales, entre ellos:
- Sector inmobiliario: interesa conocer los datos de los inmuebles de una zona concreta y elaborar informes estadísticos que indiquen cómo se encuentra el mercado en el momento. Además se pueden identificar las tendencias si realizamos un análisis con cierta recurrencia. Por ejemplo el precio del metro cuadrado en un barrio.
- Sector automotriz: al igual que con los inmuebles, el mundo del motor posee multitud de datos relevantes que pueden ayudar a tener más información sobre el mercado. Por ejemplo, el precio medio de un vehículo con determinados kilómetros.
- Sector de la tecnología: con el aumento de la tecnología en nuestras vidas, es interesante poseer datos que nos ayuden a tomar decisiones. A modo de ejemplo, conocer la tendencia de los precios de un smartphone determinado a la espera de encontrar una buena oferta.
- Sector de segunda mano: gracias a las plataformas de segunda mano como Milanuncios o Wallapop, podemos hacernos una idea de cómo va el mercado de segunda mano en prácticamente cualquier tipo de producto. Por ejemplo, descubrir productos interesantes a buen precio en el mundo de la moda como zapatillas o camisetas.
¿Cómo funciona el Web Scraping?
Para empezar a extraer datos de una web lo primero que tenemos que saber es dónde están los datos. Determina si están en una web o en una app, si esta web proporciona una API pública o no, etc. Esto nos ayudará a determinar el tipo de scraper que vamos a hacer: un navegador automático, un robot con API, etc.
A continuación necesitarás realizar una petición al sitio en concreto del que queremos extraer sus datos. Una petición es algo tan sencillo como solicitar los datos a una página web. Para los usuarios normales se trata de visitar la página web desde un navegador.
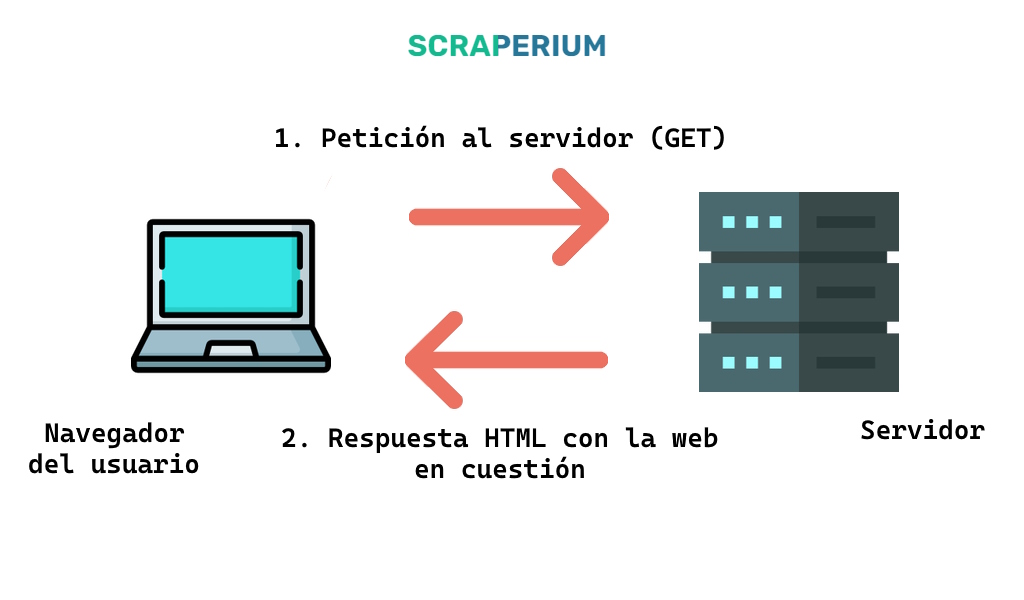
El servidor, como se puede ver en la ilustración, nos devuelve un documento HTML que el navegador web posteriormente muestra al usuario con una estructura y estilos determinados. Este proceso se conoce como renderizado de la web.
Aquí es donde viene el punto importante. Los softwares scrapers se encargan de obtener los datos que nos interesan de ese HTML. Por ejemplo, el valor numérico de la etiqueta de precios de los productos online.
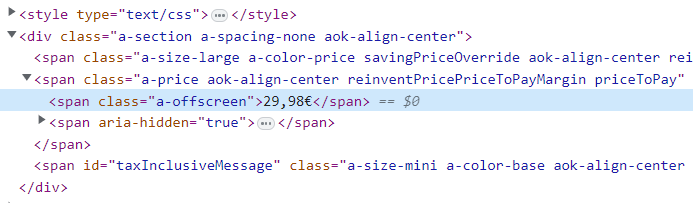
El software deberá encargarse, además, de la clasificación y almacenamiento de esos datos:
- Por clasificación nos referimos a almacenarlo en unos determinados ficheros o registros de manera organizada. Si por ejemplo estamos obteniendo los precios de los productos de Amazon, resulta interesante clasificarlos por el departamento en el que estén ubicados los productos.
- Por almacenamiento nos referimos a escribir esos datos en un formato determinado de interés. Entre los más populares destacan los formatos de celdas (CSV, XLS), formatos estructurados (JSON, XML) o formatos de base de datos (SQL).
Con el aumento de páginas web que renderizan en el lado del cliente (Client Side Rendering) gracias a tecnologías basadas en JavaScript, esta primera petición no contiene los datos. Para ello tendremos que ejecutar un navegador automatizado que no solo realice la petición al servidor sino que renderice la página web ejecutando previamente todo el JavaScript que debe ejecutarse para mostrar la información al usuario.
¿Necesito saber programar para hacer scraping?
Una pregunta frecuente en el mundo del scraping es si es necesario tener conocimientos de programación para poder hacer scraping.
Por suerte, no es necesario saber programar para empezar a scrapear. Existen múltiples programas que te ayudarán a realizar esta tarea sin escribir una sola línea de código. También puedes contactar con profesionales que te escriban un programa para ti.
Sin embargo sí tendrás que tener unos conocimientos básicos sobre HTML para extraer correctamente los datos si provienen de una página web. Puedes aprender HTML fácilmente a través de tutoriales como los de W3Schools.